Authentication¶
Authentication is crucial for securing access to Lakekeeper. By enabling authentication, you ensure that only authorized users can access and interact with your data. Lakekeeper supports authentication via any OpenID (or OAuth 2) capable identity provider as well as authentication for Kubernetes service accounts, allowing you to integrate with your existing identity providers.
Authentication and Authorization are distinct processes in Lakekeeper. Authentication verifies the identity of users, ensuring that only authorized individuals can access the system. This is performed via an Identity Provider (IdP) such as OpenID or Kubernetes. Authorization, on the other hand, determines what authenticated users are allowed to do within the system. Lakekeeper uses OpenFGA to manage and evaluate permissions, providing a robust and flexible authorization model. For more details, see the Authorization guide.
Lakekeeper does not issue API-Keys or Client-Credentials itself, as this can introduce multiple security risks. Instead, it relies on external IdPs for authentication, ensuring a secure and centralized management of user identities. This approach minimizes the risk of credential leakage and simplifies the integration with existing security infrastructures.
OpenID Provider¶
Lakekeeper can be configured to integrate with all common identity providers. For best performance, tokens are validated locally against the server keys (jwks_uri). This requires all incoming tokens to be JWT tokens. If you require support for opaque tokens, please upvote the corresponding Github Issue.
If LAKEKEEPER__OPENID_PROVIDER_URI is specified, Lakekeeper will verify access tokens against this provider. The provider must provide the .well-known/openid-configuration endpoint and the openid-configuration needs to have jwks_uri and issuer defined. Optionally, if LAKEKEEPER__OPENID_AUDIENCE is specified, Lakekeeper validates the aud field of the provided token to match the specified value. We recommend to specify the audience in all deployments, so that tokens leaked for other applications in the same IdP cannot be used to access data in Lakekeeper.
In the following section we describe common setups for popular IdPs. Please refer to the documentation of your IdP for further information.
Entra-ID (Azure)¶
We are creating three App-Registrations: One for Lakekeeper itself, one for the Lakekeeper UI and one for a machine client (Spark) to access Lakekeeper. While App-Registrations can also be shared, the recommended setup we propose here offers more flexibility and best security.
App 1: Lakekeeper UI Application¶
- Create a new "App Registration"
- Name: choose any, for this example we choose
Lakekeeper-UI - Redirect URI: Add the URL where the Lakekeeper UI is reachable for the user suffixed by
/callback. E.g.:http://localhost:8181/ui/callback. If asked, select type "Single Page Application (SPA)".
- Name: choose any, for this example we choose
- In the "Overview" page of the "App Registration" note down the
Application (client) ID. Also note theDirectory (tenant) ID.
App 2: Lakekeeper Application¶
- Create a new "App Registration"
- Name: choose any, for this example we choose
Lakekeeper - Redirect URI: Leave empty.
- Name: choose any, for this example we choose
- When the App Registration is created, select "Manage" -> "Expose an API" and on the top select "Add" beside
Application ID URI.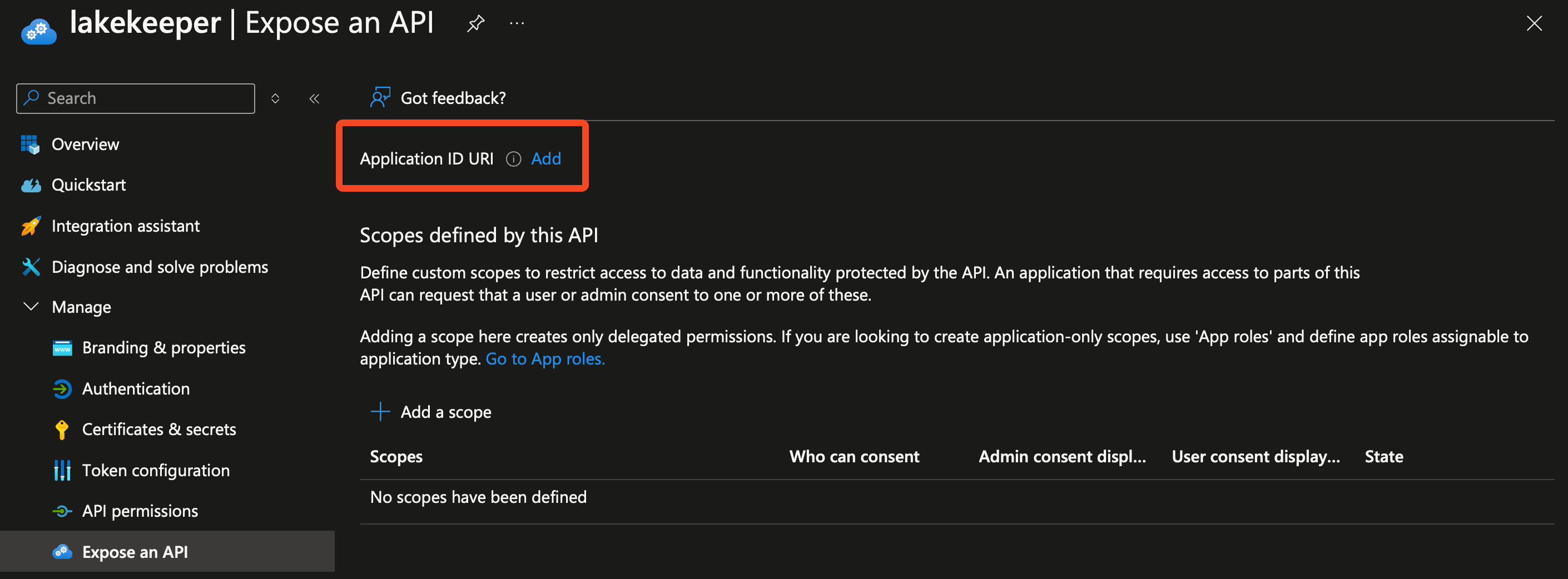 Note down the
Note down the Application ID URI(should beapi://<Client ID>). - Still in the "Expose an API" menus, select "Add a Scope". Fill the fields as follows:
- Scope name: lakekeeper
- Who can consent? Admins and users
- Admin consent display name: Lakekeeper API
- Admin consent description: Access Lakekeeper API
- State: Enabled
- After the
lakekeeperscope is created, click "Add a client application" under the "Authorized client applications" headline. Select the previously created scope and paste asClient IDthe previously noted ID from App 1. - In the "Overview" page of the "App Registration" note down the
Application (client) ID.
We are now ready to deploy Lakekeeper and login via the UI. Set the following environment variables / configurations. We are using one Application to secure the Lakekeeper API and login with UI using public flows (Authorization Code Flow):
LAKEKEEPER__BASE_URI=<URI where lakekeeper is reachable, in my example http://localhost:8181>
// Note the v2.0 at the End of the provider URI!
LAKEKEEPER__OPENID_PROVIDER_URI=https://login.microsoftonline.com/<Tenant ID>/v2.0
LAKEKEEPER__OPENID_AUDIENCE="api://<Client ID from App 2 (lakekeeper)>"
LAKEKEEPER__UI__IDP_CLIENT_ID="<Client ID from App 1 (lakekeeper-ui)>"
LAKEKEEPER__UI__IDP_SCOPE="openid profile api://<Client ID from App 2>/lakekeeper"
LAKEKEEPER__OPENID_ADDITIONAL_ISSUERS="https://sts.windows.net/<Tenant ID>/"
// The additional issuer URL is required as https://login.microsoftonline.com/<Tenant ID>/v2.0/.well-known/openid-configuration
// shows https://login.microsoftonline.com as the issuer but actually
// issues tokens for https://sts.windows.net/. This is a well-known
// problem in Entra ID.
Before continuing with App 2, we recommend to create a Warehouse using any of the supported storages. Please check the Storage Documentation for more information. Without a Warehouse, we won't be able to test App 3.
App 3: Machine User / Spark¶
- Create a new "App Registration"
- Name: choose any, for this example we choose
Spark - Redirect URI: Leave empty - we are going to use the Client Credential Flow
- Name: choose any, for this example we choose
- When the App Registration is created, select "Manage" -> "Certificates & secrets" and create a "New client secret". Note down the secrets "Value".
That's it! We can now use the second App Registration to sign into Lakekeeper using Spark or other query engines. A Spark configuration would look like:
import pyiceberg.catalog
import pyiceberg.catalog.rest
import pyiceberg.typedef
catalog = pyiceberg.catalog.rest.RestCatalog(
name="my_catalog_name",
uri="http://localhost:8181/catalog",
warehouse="<warehouse name>",
credential="<Client-ID of App 3 (spark)>:<Client-Secret of App 3 (spark)>",
scope="email openid api://<Client-ID of App 2 (lakekeeper)>/.default",
**{
"oauth2-server-uri": "https://login.microsoftonline.com/<Tenant ID>/oauth2/v2.0/token"
},
)
print(catalog.list_namespaces())
import pyspark
conf = {
"spark.jars.packages": "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.7.0,org.apache.iceberg:iceberg-azure-bundle:1.7.0",
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
"spark.sql.catalog.azure-docs": "org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.azure-docs.type": "rest",
"spark.sql.catalog.azure-docs.uri": "http://localhost:8181/catalog",
"spark.sql.catalog.azure-docs.credential": "<Client-ID of App 3 (spark)>:<Client-Secret of App 3 (spark)>",
"spark.sql.catalog.azure-docs.warehouse": "<warehouse name>",
"spark.sql.catalog.azure-docs.scope": "email openid api://<Client-ID of App 2 (lakekeeper)>/.default",
"spark.sql.catalog.azure-docs.oauth2-server-uri": "https://login.microsoftonline.com/<Tenant ID>/oauth2/v2.0/token",
}
config = pyspark.SparkConf().setMaster("local")
for k, v in conf.items():
config = config.set(k, v)
spark = pyspark.sql.SparkSession.builder.config(conf=config).getOrCreate()
try:
spark.sql("USE `azure-docs2`")
except Exception as e:
print(e.stackTrace)
raise e
spark.sql("CREATE NAMESPACE IF NOT EXISTS `test`")
spark.sql("CREATE OR REPLACE TABLE `test`.`test_tbl` AS SELECT 1 a")
If Authorization is enabled, the client will throw an error as no permissions have been granted yet. During this initial connect to the /config endpoint of Lakekeeper, the user is automatically provisioned so that it should show up when searching for users in the "Grant" dialog and user search endpoints. While we try to extract the name of the application from its token, this might not be possible in all setups. As a fallback we use the Client ID as the name of the user. Once permissions have been granted, the user is able to perform actions.
Kubernetes¶
If LAKEKEEPER__ENABLE_KUBERNETES_AUTHENTICATION is set to true, Lakekeeper validates incoming tokens against the default kubernetes context of the system. Lakekeeper uses the TokenReview to determine the validity of a token. By default the TokenReview resource is protected. When deploying Lakekeeper on Kubernetes, make sure to grant the system:auth-delegator Cluster Role to the service account used by Lakekeeper:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: allow-token-review
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: <lakekeeper-serviceaccount>
namespace: <lakekeeper-namespace>